第3章 推荐系统中的Embedding
3.1 无中生有:推荐算法中的Embedding
图3-1 推荐系统的“评分卡” #card

tf.keras.layers.Embedding 用法 #card
- string 转 int ,查表,使用
1 | import tensorflow as tf |
3.2 共享Embedding还是独占Embedding
独占 embedding 例子
比如在之前的例子中,App的安装、启动、卸载对于要学习的App Embedding有着不同的要求。#card
“安装”与“启动”两个Field要求App Embedding能够反映出App为什么受欢迎,
而“卸载”这个Field要能够反映出App为什么不受欢迎。
举个例子,有两款音乐App,它们都因曲库丰富被人喜欢,“安装”与“启动”这两个Field要求这两个音乐App的Embedding距离相近。#card
但是这两个App的缺点不同,一个收费高,另一个广告频繁,因此“卸载”Field要求这两个音乐App的Embedding相距远一些。
显然,用同一套App Embedding很难满足以上两方面的需求,所以大厂一般选择让“装/启/卸”3个Field各自拥有独立的Embedding矩阵。
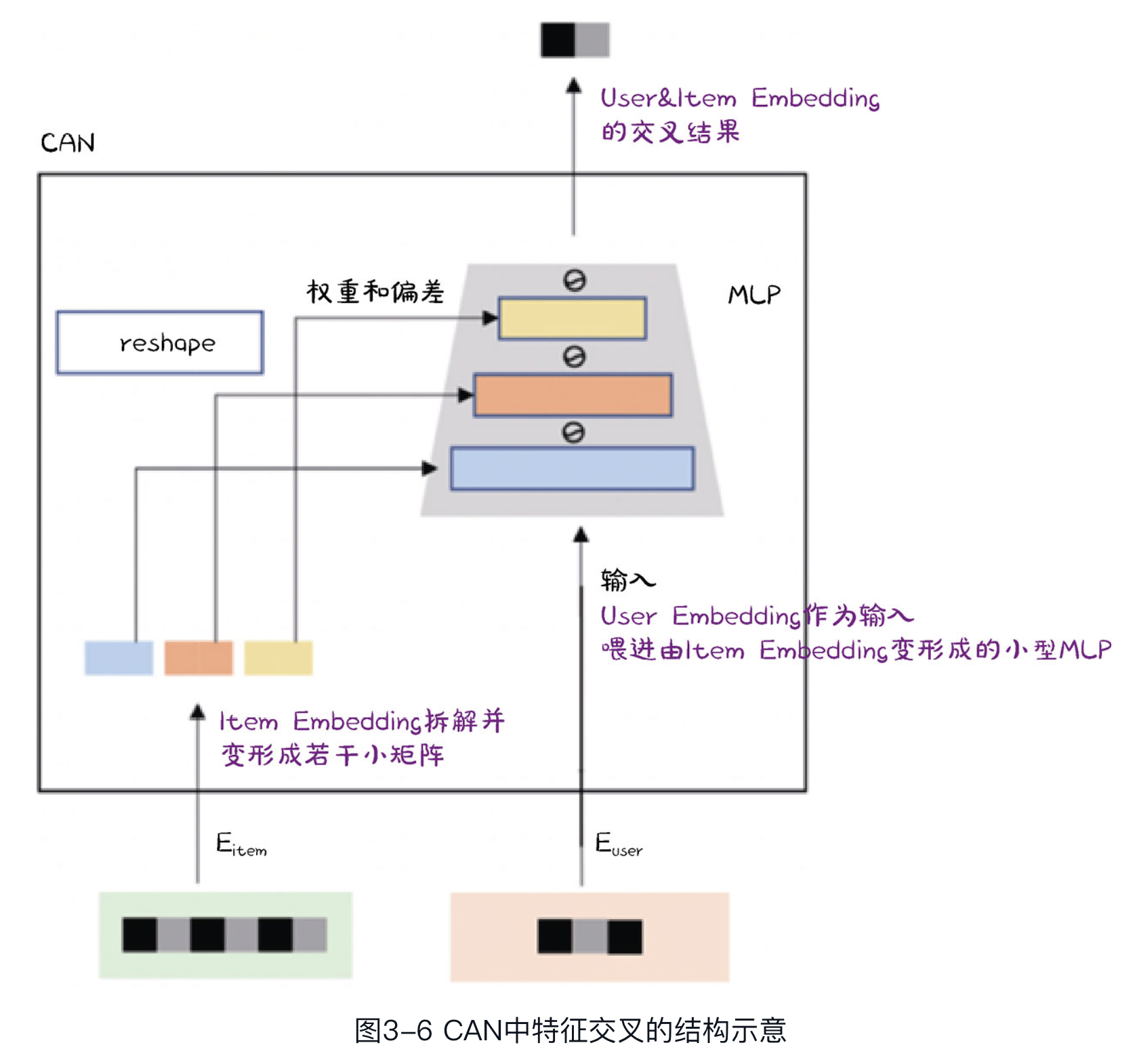
[[@CAN: Feature Co-Action for Click-Through Rate Prediction]] 的目标有两个:像FFM那样,让每个特征在与其他不同特征交叉时使用完全不同的Embedding;不想像FFM那样引入那么多参数而导致参数空间爆炸,增加训练的难度。提出的特征交叉结构 #card
3.3 [[Parameter Server]]
- 基于PS的训练流程如图3-8所示,每个步骤的具体操作描述如表3-2所示。 #card
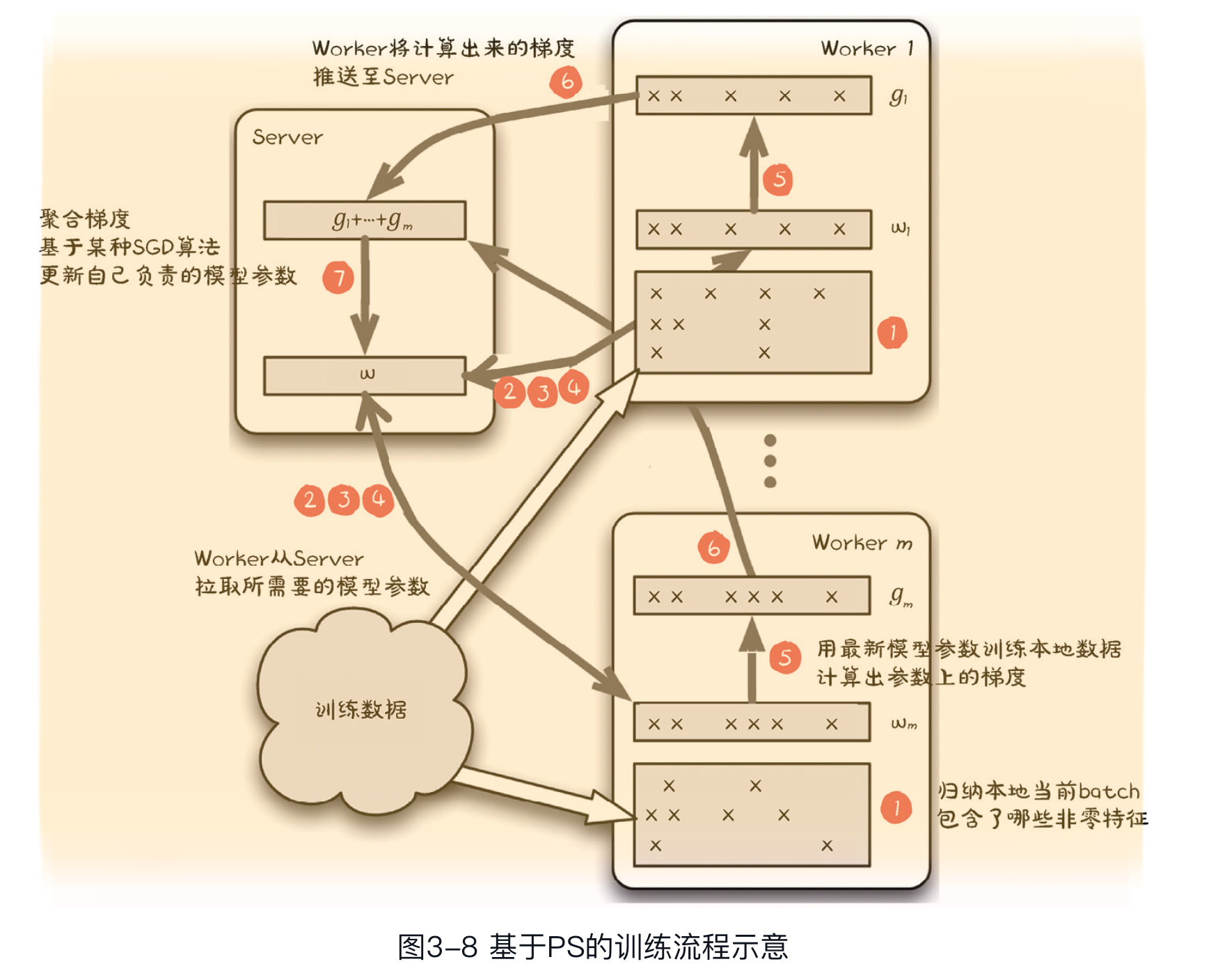

总结下来,PS训练模式是Data Parallelism(数据并行)与Model Parallelism(模型并行)这两种分布式计算范式的结合。
数据并行。#card
- 数据并行很好理解,海量的训练数据分散在各个节点上,每个节点只训练本地的一部分数据,多节点并行计算加快了训练速度。
模型并行。#card
推荐系统中的特征数量动辄上亿,每个Embedding又包含多个浮点数,这么大的参数量是单个节点无法承载的,因此必然分布在一个集群中。
接下来会讲到,由于推荐系统中的特征高度稀疏的性质,一轮迭代中,不同Worker节点不太会在同一个特征的参数上产生冲突,因此多个Worker节点相对解耦,天然适合模型并行。
第3章 推荐系统中的Embedding
https://blog.xiang578.com/post/logseq/第3章 推荐系统中的Embedding.html